Writing assembly is itself an art. When C, C++, or any other language is compiled, the compiler determines the art of writing assembly. However, this time, we will some of the techniques and decisions we can make to write these ourselves.
We will use RISC-V to see how to design logic, write up the logic, and translate the logic into assembly.
Tip 1: Design the Logic in a Comfortable Language
This is the hardest step to get right with my students. Many students want to sit down and write the complete package. However, if you’re not comfortable with assembly, this is a doomed approach. Instead, to divide the logic from the language, we have to write in a language we understand.
If a student doesn’t know C or some lower-level language, then I suggest they write in pseudocode. Too high of a language will make the translation harder and too low of a language will make the logic design harder. So, I recommend C or C++, or some language at that level.
When translating, it is helpful to have some sort of editor that can place them side-by-side. Keeping a list of instructions in your brain is difficult, especially if you’re translating a complex program.
Atom’s “split” windows.
Tip 2: Take Small Bites
Many of my students try to write the entire program from start to finish without testing anything in between. I teach incremental programming, especially for new learners. The point is to test when you get a portion of logic completed. This could be as simple as getting a for loop done, or shifting to scale a pointer.
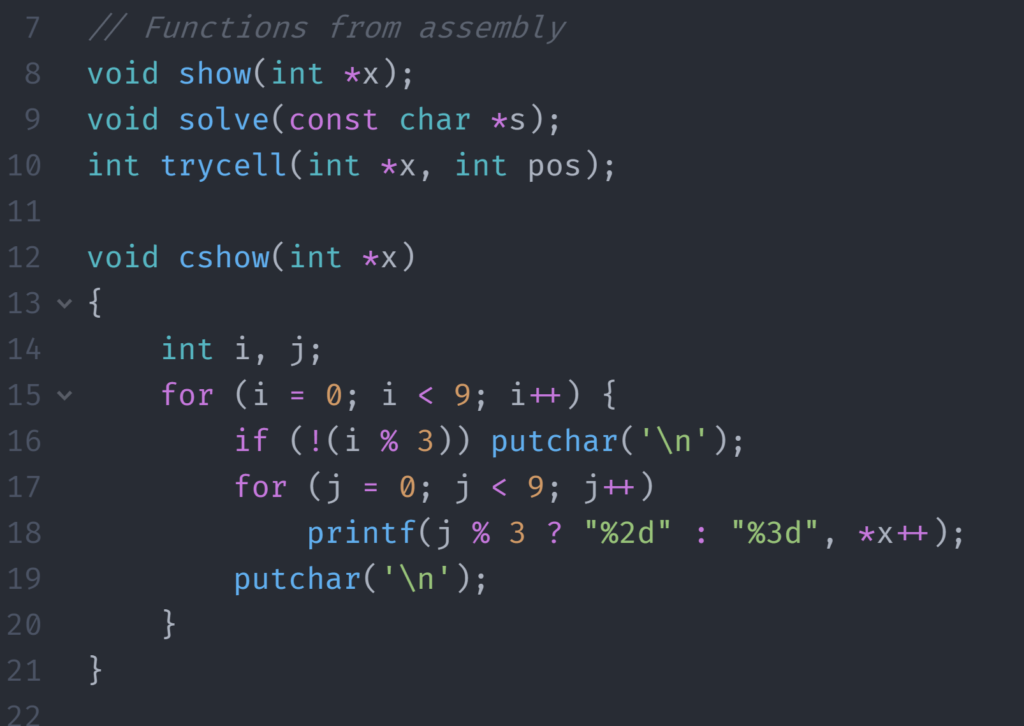
One way you can test is to link your C or C++ program with your assembly program. You can do this by prototyping the name of the assembly function in C++ and switching between the two. You need to make sure you keep the two different, otherwise your linker won’t be happy. I usually put a “c” in front of my C functions to differentiate. I don’t change the assembly names since in the end, we want all assembly functions to replace the C functions.
Combining assembly-written and C-written functions.
With what I’ve done above, we can call show to run the assembly function or cshow to run the C function. In C++, the names of the functions are mangled to allow for overloading. However, you can turn this off by doing the following:
extern "C" { // Turn off name mangling
void show(int *x);
}
The extern “C” will tell C++ that the functions follow the C “calling convention”. We really care that name mangling is turned off so that we can just create a label named “show” and have our function.
Tip 3: Know Your Role
As Dwayne “The Rock” Johnson always said, “know your role”. It is important to know what C/C++ was doing for us versus what assembly doesn’t do for us. This includes order of operations. For example, 4 + 3 * 4 will automatically order the operations to perform multiplication first, followed by addition. However, in assembly, we must choose the multiply instruction first followed by the addition instruction. There is no “reordering” performed for us.
Tip 4: Know How to Call a Function
Most ISA architectures will come with a calling convention manual, such as ARM and RISC-V. These just lay down some ground rules to make calling a function work across all languages. Luckily, the “ABI” names of the RISC-V registers really lend to what they mean. Here are some of the rules we need to abide by.
Integer arguments go in a0-a7, floating point arguments go in fa0-fa7.
Allocate by subtracting from the stack pointer, deallocate by adding it back.
The stack must be allocated in chunks of 8.
All a (argument) and t (temporary) registers must be considered destroyed after a function call. Any time I see the “call” pseudo-instruction, I start thinking about saving registers using the stack.
All s (saved) registers can be considered saved after a function call.
If you use any of the saved registers, you must restore their original value before returning.
Return data back to the caller through the a0 register.
Don’t forget to save the one and only RA (return address) register any time you see a call instruction (jal or jalr) in your function.
Obviously, I’ve reinterpreted the rules in a more informal way, but you get the jist of what’s going on here.
.global main
main:
addi sp, sp, -8
sd ra, 0(sp)
la a0, test_solve
call solve
mv a0, zero
ld ra, 0(sp)
addi sp, sp, 8
ret
You can see from the code above, we allocate our stack frame first, save all registers that need to be saved, execute, and then undo everything before returning.
Tip 5: Document!
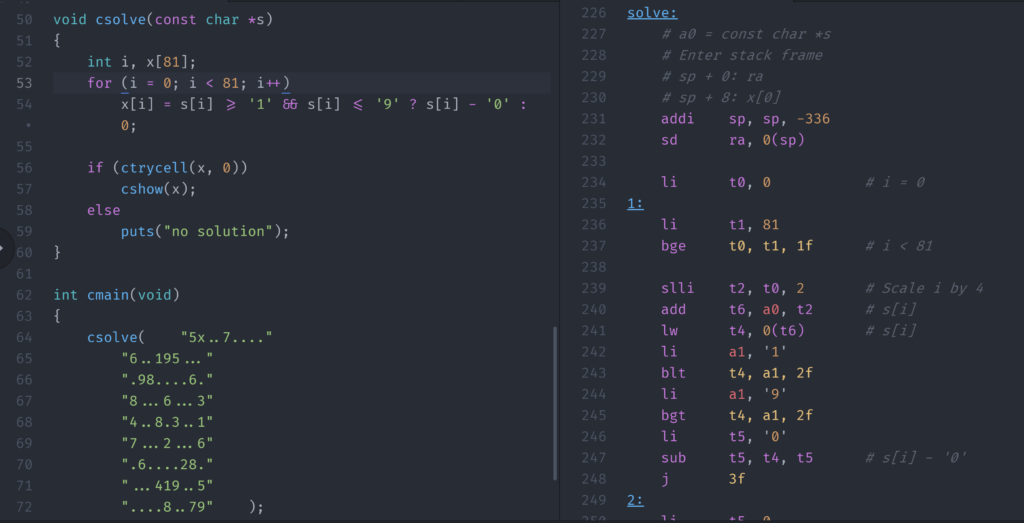
Writing assembly from C or another language will have you writing multiple lines of assembly code for every single line of C code. This can get confusing and utterly frustrating if you’re trying to debug your program. So, I always write the C code as a comment for the assembly and then pull it apart and show each step of me doing it.
# used |= 1 << ( x[i * 9 + col] - 1)
li t0, 9
mul t1, s3, t0 # t1 = i * 9
add t1, t1, s2 # t1 = i * 9 + col
slli t2, t1, 2 # Scale by 4
add t2, t2, s6 # x + i * 9 + col
lw t3, 0(t2) # x[i * 9 + col]
addi t3, t3, -1 # x[i * 9 + col] - 1
li t4, 1
sll t4, t4, t3 # 1 << x[i * 9 + col] - 1
or s5, s5, t4 # used |= ...
You can see from the code above, I have the original C code (first comment), and then inline comments for each piece. This keeps me honest when it comes to order of operations and that I’m doing each step correctly.
My last post garnered some attention by those telling me that I “forgot” to execute an SFENCE.VMA after I wrote to the SATP register–some with more tact than others. This post is here to clarify why I did what I did, and to clarify what the specification actually tells us needs to be done.
What is SATP?
The supervisor address translation and protection (SATP) register is a register that tells the MMU what mode it’s in, what address space it is working in, and where to find the first level page table in RAM (this would be level 2 for Sv39).
The SATP Register Fields
The SATP register stores three pieces of information, the MODE, the address space identifier (ASID), and the physical page number (PPN).
The MODE
If the MODE=0, then the MMU is turned off and any address is not translated.
If MODE=8, we’re in Sv39 (Supervisor 39-bit) mode which means that our virtual addresses are 39-bits long.
There are other modes, but I won’t cover them here.
The ASID
The address space identifier tags translations with a unique identifier.
The PPN
The physical page number is the upper 44-bits of a 56-bit memory address where we can find the first level page table.
What is SFENCE.VMA?
In absolute terms, this means supervisor fence.virtual memory address. In real terms, it will flush the cache’s so that the MMU will “see” the new changes in memory. This means that the MMU will be forced to look in RAM where the page tables are stored.
The SFENCE.VMA instruction has several different ways to execute it as shown in the specification. This should clue us in to the fact that executing SFENCE.VMA every time we write to SATP might not be so cut and dry.
What is Happening?
So, why is this not straightforward? The issue is that “walking” a page table–meaning going into RAM and translating a virtual address into a physical address–is not a fast process. There are multiple levels of page tables, and several 8-byte entries that need to be dereferenced by the memory controller.
We can speed these walks up by “caching” frequently translated addresses into a table. The table has the virtual address number and the physical address number, so translation is just a table lookup instead of dereferencing several levels of page tables.
This caching can be speculative. If the MMU doesn’t speculate, then the first time we translate an address, that address will not be in the TLB (the cache table) and we will get what is known as a compulsory miss. If we speculate, we can predict the addresses that will be used and when the memory controller isn’t doing anything else, we can load the virtual address and physical address into cache.
This speculation is one of the reasons for SFENCE.VMA. Another reason is due to the fact that when we translate a page using the MMU, it stores the most recent translations in the TLB as well.
The Translation Lookaside Buffer
The translation lookaside buffer or TLB is a fancy term for the MMU cache. It stores the most recent translations to exploit temporal locality–that is, the chances we’re going to translate the same address near in the future is likely. So, instead of having to walk the page tables all over again, we just look in the TLB.
The TLB has several entries, and with RISC-V, it stores an address space identifier (ASID). The address space identifier allows the TLB to store more entries than just the most recent page table. This has always been a problem with TLBs, including with the Intel/AMD processor. Writing to its MMU register (called CR3 for control register #3) will cause a TLB flush. This is NOT the case with RISC-V writing to the SATP register (the MMU register in RISC-V).
The specification just gives the general rules for a manufacturer to use. Therefore, the manufacturer can choose how they want to implement their MMU and TLB as long as it complies with RISC-V’s privileged specification. Here’s a simple implementation of a TLB that complies with the privileged specification.
Conclusion
The RISC-V specification doesn’t make it very clear, but you can see clarification on the spec’s github repository. If the MODE is not 0, then the MMU is allowed to speculate, meaning it can pre-populate the MMU based on the addresses it thinks will need to be translated in the near future. The specification allows this, but the MMU cannot throw a page fault if a speculatory translation is invalid.
So, bottom line — SFENCE.VMA should NOT be called every time SATP is changed. This will cause TLB thrashing since every time you context switch, you will need to change the SATP register to the kernel page table, schedule, then change the SATP register to the new scheduled process’ page table.
Instead, the SFENCE.VMA instruction should be invoked when one or more of the following occur:
When software recycles an ASID (i.e., reassociates it with a different page table), it should first change satp to point to the new page table using the recycled ASID, then execute SFENCE.VMA with rs1=x0 and rs2 set to the recycled ASID. Alternatively, software can execute the same SFENCE.VMA instruction while a different ASID is loaded into satp, provided the next time satp is loaded with the recycled ASID, it is simultaneously loaded with the new page table.
If the implementation does not provide ASIDs, or software chooses to always use ASID 0, then after every satp write, software should execute SFENCE.VMA with rs1=x0. In the common case that no global translations have been modified, rs2 should be set to a register other than x0 but which contains the value zero, so that global translations are not flushed.
If software modifies a non-leaf PTE, it should execute SFENCE.VMA with rs1=x0. If any PTE along the traversal path had its G bit set, rs2 must be x0; otherwise, rs2 should be set to the ASID for which the translation is being modified.
If software modifies a leaf PTE, it should execute SFENCE.VMA with rs1 set to a virtual address within the page. If any PTE along the traversal path had its G bit set, rs2 must be x0; otherwise, rs2 should be set to the ASID for which the translation is being modified.
For the special cases of increasing the permissions on a leaf PTE and changing an invalid PTE to a valid leaf, software may choose to execute the SFENCE.VMA lazily. After modifying the PTE but before executing SFENCE.VMA, either the new or old permissions will be used. In the latter case, a page fault exception might occur, at which point software should execute SFENCE.VMA in accordance with the previous bullet point.
Unfortunately, you have to dig through the issues and updates to the specification on GitHub to find out some of this information. I have provided links in references below.
If you are living under a rock, quarantined against COVID-19, here’s quite a long, and somewhat technical, post for your consumption. This post will talk about how C and assembly dance together–the tango? waltz? who knows?
I usually write about operating systems, but I have not been able to write an operating system completely in one language. It probably can be done, but for me I write the bootloader and some utilities purely in assembly.
I will be using the RISC-V architecture to describe how C translates into assembly. The nice thing about C is that there are only a fair amount of abstractions, so we can take a statement of C and translate it into assembly.
I teach my students to develop their logic in a higher-level language (mainly C++) and then translate into assembly. Assembly requires you to keep several things in your head at once, even to write a simple for loop. Luckily, there are some macros in assembly to make it a bit easier.
Let’s not forget that when we compile C code, we get assembly files. You can see the intermediate assembly file by using the -S switch to gcc. Otherwise, gcc will typically put the assembly file in the /tmp/ directory.
gcc -S test.c
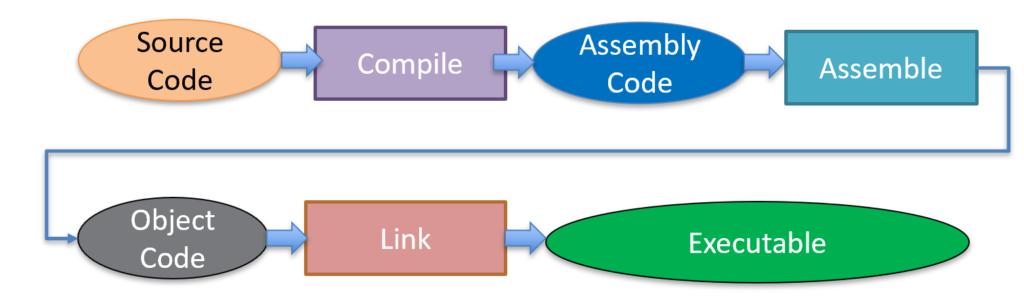
Technically, C doesn’t have to compile into assembly, but as far as I know, nearly all compile into some lower-level language, and not directly into machine code (object code).
So, to get code into machine instructions, we have to follow the steps below:
An executable is a special type of machine code. Executables are usually in a specific format that the operating system can understand. However, inside of the executable is a section called the text section. This is where the machine code is stored. In Linux, this is called an executable and linkable format or ELF file. In Windows, this is called a portable executable or PE.
Why Assembly?
Assembly has many additional abstractions on top of it, including macros, labels, and pseudo-instructions. Yes, that’s right, assembly will do many things for you. However, the nice thing about assembly is that one instruction more-or-less is really one instruction (except maybe with pseudo-instructions). That is, we don’t let any compiler tell us how it wants to do things. If we want to make the addition operator (+) preferred over the multiplication operator (*), we can do it. Why would we do that? Uhh.. Ask someone else.
Another reason we use assembly over a high-level language is to use instructions that C or C++ cannot really use. For example, the advanced vector extensions (AVX) for an Intel processor don’t have a 1-to-1 conversion from C. Now, many compilers have done some work with this using what are known as intrinsics. (EDITED): These instrinsics are assembly wrappers on top of C. So, we can’t get by with C doing the hard part for us. Where as int i = 10 * z; will produce the assembly we need to get the result, the intrinsics are C-syntax for assembly instructions. So, all in all, we still need to know what the assembly is doing.
An optimizing compiler might be able to make some improvements with the assembly, but let’s take a look at two different ways to do matrix multiplication using SSE in Intel. One, we use the intrinsic instructions in C and in the other, we use assembly directly.
The code above multiplies a 4×4 matrix with a 4 element vector. However, if you look at how to multiply matrix by a vector, you see that we can parallelize each row, which is what I’m doing up here. So, first, we loadu (load unaligned) using ps, which stands for packed single. This means that it will grab 4, 32-bit floats and put them into a single 128-bit register. Then we multiply the matrix row with the vector. That’ll give us 4 elements all multiplied together. Then, we need to add all four elements together to get a single value, which is the result of the vector at that element. Each haddps instruction adds two elements together. To get all four elements added, we run the instruction twice.
You can see that in C, this looks fairly easy to do, but we still need knowledge of what the instruction is doing. If I write the assembly, as below, I can group certain operations and use the larger register set to my advantage. See below.
Either way you slice it, we’re writing assembly either in a .S file or as the intrinsics, such as _mm_haddps.
C Calling Conventions
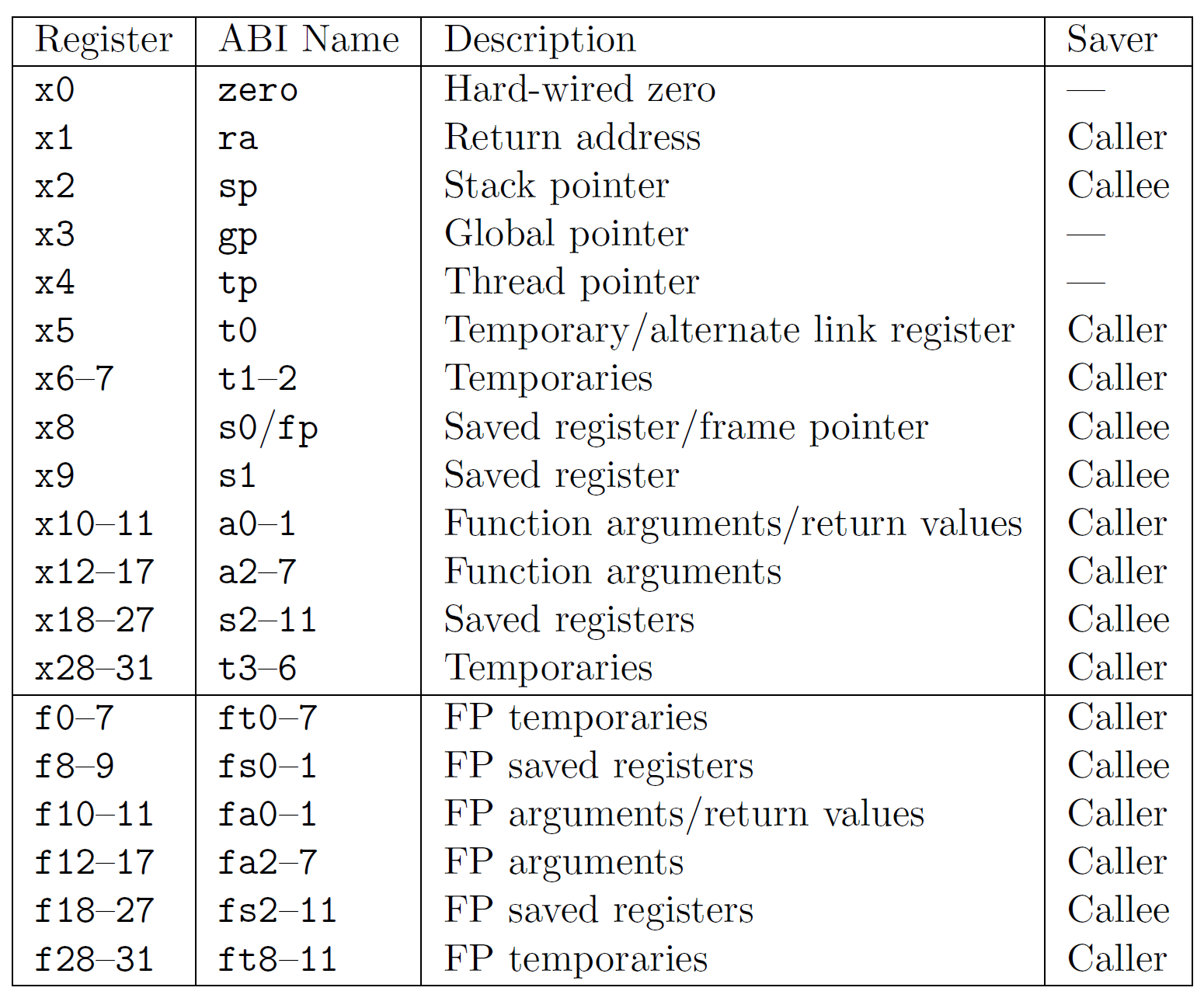
C has a standard for most architectures called the ABI, which stands for application binary interface. We use this standard so that any language can talk to another, as well as the architecture, provided they use the standard. Some things about the C calling conventions include what registers get what values whenever we call a function. Furthermore, it specifies which registers can be destroyed by the called function and which must be preserved. In RISC-V, the actual RISC-V specification has an Assembly Programmer section, which defines the following for the registers.
You can see that the registers have two names, one that starts with x and the other that starts with a, s, t, and some others. These are referring to the same registers, but x just gives you a number for that register. The a stands for argument, the t stands for temporary, and the s stands for saved. These are called ABI names for the registers, and then the description tells you what the ABI recommends each register should do. Finally, notice that there is a column called Saver. Again, we have to know which registers we’re responsible for.
Register Sizes
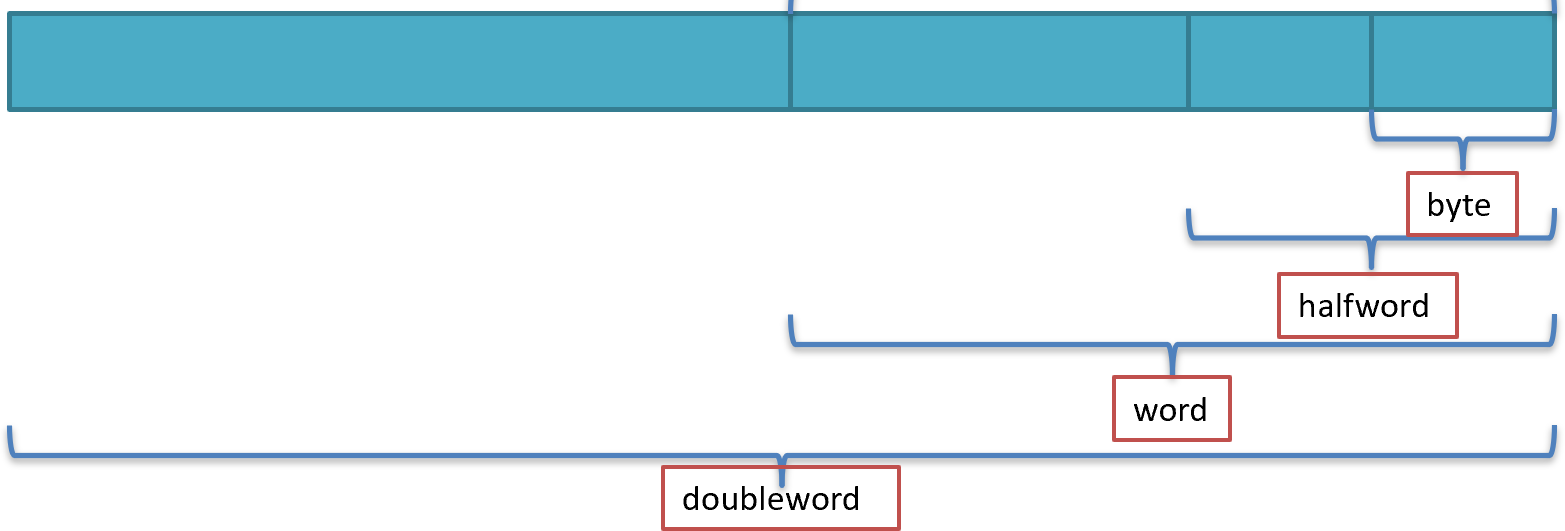
The load and store instructions can have one of four suffixes: b, h, w, or d, which stands for byte, halfword, word, and doubleword, respectively. A word in RISC-V is 32 bits or 4 bytes.
Each register in RISC-V is either 32 bits (for RV32) or 64 bits (for RV64). So, even though we load a byte from memory, it is still being stored into a bigger register. With the vanilla load and store instructions, the value will sign-extend from 8 bits to 64 bits.
Caller vs Callee Saved
Saving registers is important because we call both scanf and printf. A callersaved register means that when we call scanf and printf, we are NOT guaranteed that the value we put in that register is the same as when the function returns. Most argument and temporary registers follow this convention.
A callee-saved register means that when we call scanf and printf, we are guaranteed that the value we put in these registers is the same when scanf and printf return. This means that scanf and printf are allowed to use the saved registers, but they are required to restore their old values before they return.
Generally, all argument and temporary registers are free to be destroyed by a function, but all saved registers must be saved. For all of this to work, C must be aware of what to do with these registers.
C and Assembly Code
When I teach my students how to encode (from assembly to machine) and decode (from machine to assembly) instructions, it is easy to see that each instruction encodes into exactly 32-bits in RISC-V (not counting the compressed instructions). However, I’m not exactly sure how I would teach that using C. Let’s take a simple C program and see how it would translate into RISC-V assembly.
#include <stdio.h>
int main() {
int i;
scanf("%d", &i);
printf("You gave %d\n", i);
return 0;
}
This translates into RISC-V assembly as:
.section .rodata
scanf_string: .asciz "%d"
printf_string: .asciz "You gave %d\n"
.section .text
.global main
main:
addi sp, sp, -16
sd ra, 0(sp)
la a0, scanf_string
add a1, sp, 8
call scanf
lw a1, 8(sp)
la a0, printf_string
call printf
ld ra, 0(sp)
addi sp, sp, 16
jr ra # same as ret instruction
The code above produces the following output. I gave 100 as an input for scanf:
First, in C, all strings are read-only global constants. The directive .asciz above means that we have an ASCII-table string with a zero on the end of it. This is how C builds a string. So, C, knows the starting memory address and goes character-by-character until it hits a zero. So, in other words, C-style-strings are arrays of characters.
.section .rodata
scanf_string: .asciz "%d"
printf_string: .asciz "You gave %d\n"
So, the portion above labels these strings as scanf_string and printf_string. A label is just like a variable–it’s just a nice name for a memory location.
.section .text
.global main
main:
The .text section is also called the code section, and it is in this section we place CPU instructions. The directive .global main makes the label, main, viewable outside of this assembly file. This is necessary because the linker will look for main. Then, we have a label called main. You can see that a function is just simply a memory label where we can find the CPU instructions for that given function.
In C, every function must have a unique name. So, a C function’s name directly corresponds with the assembly’s memory label. In this case, main is the label for int main().
addi sp, sp, -16
sd ra, 0(sp)
The sp register stores the stack pointer. The stack is memory storage for local variables. Whenever we allocate memory from the stack, we decrement. Then, we own everything between what we decremented and the original value of the stack pointer. So, in the case above, main now owns sp – 16 through (but not including) sp. Again, sp is just a memory address.
The instruction sd stands for store-doubleword. In this case, a double word is 64 bits or 8 bytes. We are storing a register called ra which stands for return address. There is only one RA register, so whenever we call another function, such as scanf and printf, it will get overwritten. The purpose of this register is so printf and scanf can find their way back to main. Since these functions can be called from anywhere, it must have a return path…hence the return address.
la a0, scanf_string
add a1, sp, 8
call scanf
Before we make a function call, we have to make sure the registers are setup before we make the call. Luckily, RISC-V makes this easy. The first argument goes into register a0, the second into a1, and so forth. For scanf, the first argument is a pointer to a string. So, we use the la (load address) instruction, which is actually a pseudo-instruction, to load the address of scanf_string into the first argument register, a0.
The second parameter is &i in C, which is the memory address where we want to store what we scan. In this case, i is a local variable, so we store it on the stack. Since bytes 0, 1, 2, …, 7 are being taken by the RA register, the next available offset we have is 8. So, we can add sp + 8 to get the memory location where we can put the value we scan.
lw a1, 8(sp)
la a0, printf_string
call printf
The code above loads a word, which is 32 bits or 4 bytes, from sp + 8, which recall is where scanf scanned our integer. This goes into the second argument, a1. Then, we load the address of the printf_string and store that memory address into the register a0.
Pointers and References
What do pointers and references mean in assembly? In C, we know that a pointer is an 8 or 4-byte memory value that stores a memory address. So, it’s like inception where a memory address stores a memory address. In assembly, we get a memory address inside of our argument registers instead of a value. Here’s an example.
Notice that we store a0 into 8(sp). This is a memory location. So, when we ld a1, 8(sp) for the scanf call, a1 will be populated with the memory address that value points to, and hence, scanf will store the value inside of there. Notice that even though it is an integer pointer, we use ld and sd (doubleword). This is because we’re not storing the value, we’re storing the memory address, which on a 64-bit machine is always 64 bits (8 bytes).
To demonstrate pointers, lets do something simple, except let’s get a reference instead of a value:
int work(int *left, int *right) {
return *left + *right;
}
While we pass addresses around, nothing really changes. However, when we dereference to get the value out of the memory address, we must use a load instruction.
.section .text
.global work
work:
# int *left is in a0
# int *right is in a1
# Use lw to dereference both left and right
lw a0, (a0)
lw a1, (a1)
# Now, add them together
add a0, a0, a1
ret
Whatever we leave in the a0 register is what is returned. That’s why our ABI calls the a0 register the “function arguments / return value”.
Structures
A structure is just multiple data in contiguous memory. The hard part comes from the fact that the C compiler will try to make memory accesses as efficient as possible by aligning data structures to their sizes. I will show this below.
struct SomeStruct {
int a;
int b;
int c;
};
Above, when we allocate memory for SomeStruct, we need 12 bytes (one integer is 4 bytes). In memory, bytes 0, 1, 2, 3 are taken by a, 4, 5, 6, 7 are taken by b, and 8, 9, 10, 11 are taken by c. So, in assembly, we can just look at the offsets 0, 4, and 8 and use lw (load word) to load from this structure.
So, let’s use this structure to see what it looks like in assembly.
.section .text
.global work
work:
# s->a is 0(a0)
# s->b is 4(a0)
# s->c is 8(a0)
lw t0, 0(a0) # s->a
lw t1, 4(a0) # s->b
lw t2, 8(a0) # s->c
mul t1, t1, t2
add a0, t0, t1
ret
The a0 register stores the memory address where the structure starts. Then, we calculate offsets for each one of the elements a, b, and c. However, this is an easy example. There are two other examples we must explore: (1) heterogeneous data types and (2) structures in arrays.
Heterogeneous Data Types
What happens when we have multiple data types inside of a structure? The C compiler tries to make the memory controller’s work easy, so it will pad the structure so that when we access a field in a structure, it only takes one request from the memory controller. With heterogeneous data types, this means we have to waste a little bit of memory.
Take the following structure for example:
struct SomeStruct {
char a;
int b;
short c;
};
The structure above has 1-byte, 4-byte, and 2-byte fields, so does that mean this structure is \(1+4+2=7\) bytes? The answer is no, the reason is padding. C will pad each element so that the \(\text{offset}\%\text{size}=0\). That is, when we look at the offset of the element, it must be evenly divisible by the size of the field.
When I teach my students, I have them draw a name, offset, size table (NOS table). In here, we can see what’s going on, and it makes it easy to translate into assembly.
Name
Offset
Size
char a
0
1
int b
4
4
short c
8
2
We can see with the table above that int b starts at offset 4. So what happened to bytes 1, 2, and 3? Those are wasted in the form of padding. So, now we can figure out the offset of each element, so the following is now translatable:
We saw that with three integers in a structure, we had offsets 0, 4, and 8. Well, lookie here! They are the same. The only thing we need to change is how we load. We look at the size column. Recall that 1 byte is a byte (lb/sb), 4 bytes is a word (lw/sw) and 2 bytes is a halfword (lh/sh).
.section .text
.global work
work:
lb t0, 0(a0) # s->a
lw t1, 4(a0) # s->b
lh t2, 8(a0) # s->c
mul t1, t1, t2
add a0, t1, t0
ret
Structures in Arrays
C allows any data structure to be stored in an array. An array is simply a memory address with like fields, however those like fields can be structures. The following diagram shows how an integer-only array with 5 elements would look in memory:
You can see the formula \(\text{address}=\text{base}+\text{offset}\times\text{size}\). So, if our base is a (let’s say 0 for now), then a[4] would be \(0+4\times 4=16\).
For structures, there can possibly be padding at the end of the structures. This padding is only for arrays. Remember that we need offset % size be zero. When looking for the amount of padding at the end of the structure, we take the remaining offset and % by the largest field. We pad until this is zero.
Let’s see how a structure would look in memory.
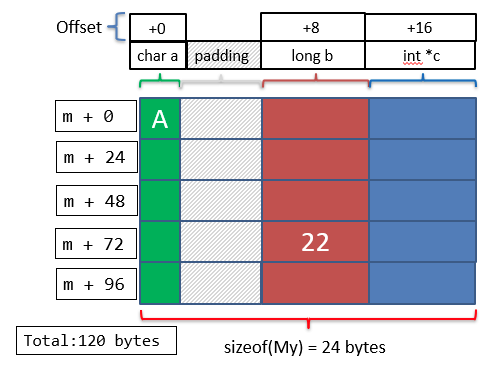
struct My {
char a;
long b;
int *c;
};
struct My m[5];
m[0].a = 'A';
m[3].b = 22;
We have an array of five of these structures. Each element has fields a, b, and c. Below is a diagram of what our memory looks like:
Globals
Recall that C generally uses the stack for local variables. However, C allows for global variables. Globals are stored in one of three sections: .rodata, .data, or .bss. The .rodata (read only data) stores global constants, the .data stores global, initialized variables, and the .bss stores global, uninitialized variables or global variables initialized to 0.
The BSS section is the weirdest one here. This section is automatically cleared to 0 by the operating system. So, any uninitialized variable actually has a defined value–0.
We can see these sections in action by looking at a C example:
#include <stdio.h>
int data = 100;
const int rodata = 200;
int bss;
int main() {
printf("%d %d %d\n", data, rodata, bss);
return 0;
}
If we look at what this produces, we see the following:
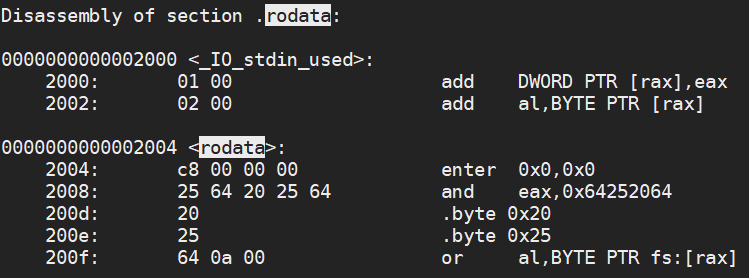
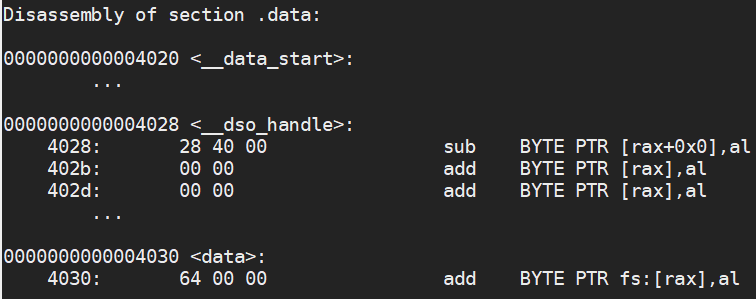
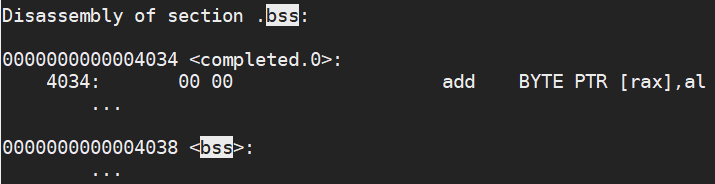
We can see that our rodata constant has the memory address of 0x2004 and has the value 0x00_00_00_c8 which is 200, our data variable has the memory address 0x4030 and has the value 0x00_00_64 which is 100. Finally our bss variable is stored at memory address 0x4038 and will have the value 0. The section only stores where the variable is located, not what is in it. The operating system itself will look at this section and assign all variables the value 0.
Conditions and Loops
Conditions are made by using a branch instruction. Some architectures support adding conditions to each instruction, but that is becoming more rare as architectures advance. Instead, we branch to a different label to either jump over code or jump into code. Let’s take a look at a for loop to see how it would look in assembly.
for (int i = 100;i >= 0;i--) {
printf("%d\n", i);
}
The assembly equivalent would be something like the following:
.section .rodata
printf_string: "%d\n"
.section .text
.global main
main:
addi sp, sp, -16
sd s0, 0(sp)
sd ra, 8(sp)
li s0, 100 # int i = 100
1:
blt s0, zero, 1f # if i < 0, break the loop
la a0, printf_string
mv a1, s0
call printf
addi s0, s0, -1 # i--
j 1b
1:
ld s0, 0(sp)
ld ra, 8(sp)
ret
So, if statements and loops conditionally execute code by using a branch instruction. In RISC-V, our branch instruction compares two registers. If those registers meet the condition, we go to the label (1f = label 1 forward, 1b = label 1 backwards). If the registers don’t meet the condition, the instruction has no effect and we move to the next instruction.
Data Types
The purpose of data types in C (when considering assembly) is to make sure we choose the correct load/store size (byte, halfword, word, and doubleword), however we also need to choose the correct operations. Most unsigned integers will zero-extend when a smaller data size is widened into a larger data size. For example:
unsigned char a = 100;
unsigned int b = (unsigned int)a;
The variable ‘a’ is only 8 bits, however it will widen to 32 bits. There are two ways we can widen a small data size into a larger data size. We can zero extend, by occupying the newly allocated space with zeroes. Or, we can sign extend, by taking the sign bit and replicating it over the new space. The choice depends on the data size. However, in assembly, it actually requires a different instruction. For example:
lb t0, 0(sp)
lbu t1, 0(sp)
The ‘lb’ (load byte) instruction will sign extend an 8-bit value in sp + 0 into a 64-bit register t0. The ‘lbu’ (load byte unsigned) instruction will zero extend an 8-bit value in sp + 0 into a 64-bit register t1. In RISC-V, we’re always dealing with a 64-bit register. C will make the distinction when emitting instructions between char, short, int, and longs.
Another occasion becomes what to do with a right shift (>>). There are actually two right shifts–logical and arithmetic. A logical right shift is used for unsigned data types and zeroes are inserted in the most significant digits place whenever bits are shifted right. An arithmetic right shift is used for signed data types and the sign bit is duplicated every time we shift right.
unsigned int a = 64;
int b = -64;
a = a >> 1;
b = b >> 1;
The variable ‘a’ above will be logically right shifted one place, which will give us 32. The variable ‘b’ will be arithmetically right shifted one place. If we did a logical shift, this would turn into a positive number. Since we duplicated the sign bit, ‘b’ becomes -32.
li t0, 64
li t1, -64
srli t0, t0, 1
srai t1, t1, 1
Conclusion and Further Reading
All in all, the compiler, when emitting its assembly code, must make these decisions. One data type of note is char. The standard does not 100% state whether we should sign extend or zero extend a char. In fact, I noticed a difference between GNU’s RISC-V toolchain vs GNU’s Intel/AMD toolchain. The former will sign extend, whereas the latter zero extends.
To see what a compiler is doing, it helps to look at the assembly code. GNU Binutils has objdump that can disassemble machine code back into assembly code. However, there may come a time where we look at the C code to see what a certain language’s compiler is doing. Who knows?
I was pretty light on the specifics when it comes to compiling. I recommend my colleague and friend’s blog about compilers here: http://austinhenley.com/